You and Your LLM Can't Review Thousands of PRs at Once — But a Graph Database Can
 146 open PRs. 83 of them clustered into conflict groups. Some modifying the same function across 5 different branches. This isn’t a hypothetical — it’s the real state of the qwen-code repository on a random Tuesday in May 2026. And qwen-code isn’t even the extreme case — projects like OpenClaw and Hermes routinely carry thousands of open PRs.
146 open PRs. 83 of them clustered into conflict groups. Some modifying the same function across 5 different branches. This isn’t a hypothetical — it’s the real state of the qwen-code repository on a random Tuesday in May 2026. And qwen-code isn’t even the extreme case — projects like OpenClaw and Hermes routinely carry thousands of open PRs.
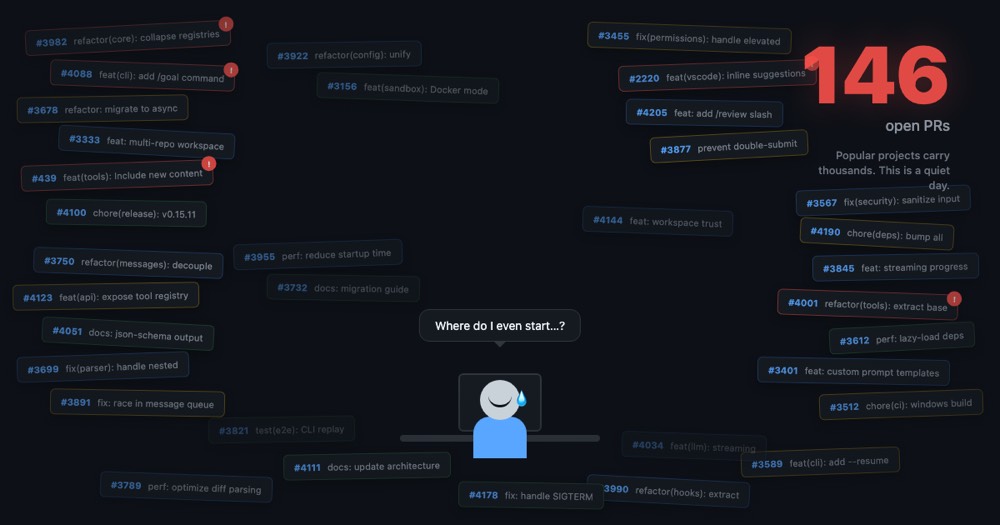
Manually reviewing this many PRs is impractical, and hidden conflicts between them are nearly impossible to spot — even for an LLM. This post shows how CodeGraph — a code analysis tool powered by the NeuG embedded graph database — transforms PR management from “intuition-driven” to “data-driven,” using a real-world analysis of qwen-code’s 146 open PRs.
The PR Review Bottleneck: Why Neither You Nor Your LLM Can Keep Up
Picture this: you’re the maintainer of a popular open-source project. You open GitHub in the morning and find 146 PRs waiting for review. They come from contributors around the world — some touch core configuration, some refactor the tool invocation pipeline, some just fix a typo in the docs. Worse still, several of them modify the same function — merging any one could break the others.
Traditional manual review has three fundamental limits:
- Scale: you can only review one PR at a time, and 146 doesn’t fit in anyone’s morning.
- Association blindness: no human can mentally track which PRs touch the same function, let alone whether PR A and PR B both modify the same underlying logic.
- Gut-based risk: “this looks risky” isn’t a metric — there’s no structural risk assessment.
What about using LLMs? Current AI Code Review solutions feed PR diffs one by one to a language model. This works at small scale, but at 146 PRs, token consumption explodes — and more critically, LLMs cannot natively perform cross-PR correlation analysis. Each invocation sees only a single PR’s diff and cannot answer global questions like “which other PRs touch the same function as this one?”
CodeGraph takes a different path: structural analysis via graph database, not only text comprehension via LLM. It indexes a code repository into a queryable knowledge graph — functions, call chains, classes, files, PRs — then runs risk scoring, conflict detection, and blast radius computation as graph queries. Zero token cost, yet capable of answering the global correlation questions that neither humans nor LLMs handle well.
How CodeGraph Works: From Repository to Knowledge Graph
CodeGraph is built on NeuG — an open-source, embedded graph database that speaks Neo4j-compatible Cypher. NeuG runs in-process (no server deployment needed), giving you the expressive power of graph queries with the simplicity of a local database file.
The pr-review workflow consists of two phases:
# Phase 1: Analyze + Detect + Persist
codegraph pr-review prepare --db .codegraph --repo owner/repo
# Phase 2: Label + Comment on GitHub
codegraph pr-review label --db .codegraph --repo owner/repo
During prepare, CodeGraph fetches all open PRs, parses their diffs at function granularity, and writes the results into the graph database — PR nodes, Function nodes, and CHANGES edges connecting them. This data coexists with the existing code structure graph (call relationships, file ownership, class hierarchies), enabling cross-PR and cross-code queries in a unified model.
The key insight: once PRs are modeled as graph nodes connected to the functions they modify, questions like “which PRs conflict?” become simple graph traversals — no pairwise diff comparison needed.
146 PRs in QwenLM/qwen-code: A Real-World Analysis
We ran CodeGraph on QwenLM/qwen-code — an active open-source AI coding assistant project. At the time of analysis (commit 870bdf2a, 2026-05-13), it had 146 open PRs. Here’s what CodeGraph found.
Per-PR Risk Scoring
For each PR, CodeGraph performs structural risk scoring — not by counting diff lines, but by parsing every hunk to identify modified, added, and deleted functions, then computing a composite score from:
- Interface change: modifying an abstract class or interface definition (e.g., a
Toolbase class method signature) - Config file: touching config/schema files (e.g.,
settings.json,tsconfig.json) - Cross-module: spanning multiple modules (e.g., modifying both
cli/andcore/) - Dead code: introducing uncalled functions
- Blast radius: the upstream/downstream call scope of modified functions (
fan_in × fan_out)
Each PR receives a risk level — LOW / MEDIUM / HIGH / CRITICAL:
Risk distribution: 🔴 CRITICAL: 10 · 🟠 HIGH: 32 · 🟡 MEDIUM: 63 · 🟢 LOW: 40
Cross-PR Conflict Detection
This is CodeGraph’s most distinctive capability. When two PRs modify the same function, they become connected through that Function node in the graph. Finding all such conflicts is a single Cypher query:
MATCH (pr1:PR)-[c1:CHANGES]->(f:Function)<-[c2:CHANGES]-(pr2:PR)
WHERE pr1.id < pr2.id
AND c1.info IN ['hunk', 'deleted']
AND c2.info IN ['hunk', 'deleted']
RETURN pr1.id, pr2.id, f.name, f.file_path;
On top of these pairwise conflicts, a Disjoint Set Union (DSU) algorithm computes connected components — each component becomes a “conflict group” of PRs that share modification targets, directly or transitively.
Result: 83 of 146 PRs clustered into 4 conflict groups.

The Three Categories
CodeGraph automatically classified all 146 PRs into actionable categories:
| Category | Count | Action |
|---|---|---|
| Auto-merge candidates | 31 | LOW risk, zero conflicts — fast-track merge |
| Independent review | 32 | Non-trivial risk but no cross-PR conflicts — review in any order |
| Conflict groups | 83 (4 groups) | Shared function modifications — coordinated review needed |
Auto-merge candidates (31 PRs) are the low-hanging fruit — release automation, pure docs, config bumps. These can go through a “lightweight review” track without blocking anything:
- #4100
chore(release): v0.15.11— Release automation, zero risk - #4051
docs: --json-schema structured output user and design docs— Pure documentation
Independent review (32 PRs) carry real risk but can be reviewed in isolation:
- #439
feat(tools): Include the new content after edits— CRITICAL, blast radius = 100. Touches both config schema and the tool pipeline, but conflicts with no other PR.
Conflict Group 1 (77 PRs) is the real battleground — the repository’s most complex conflict network, with all PRs connected through shared function modifications:
- #3982
refactor(core): collapse three task registries into one— CRITICAL, blast radius = 132, interface changes across 5 files - #4088
feat(cli): add session-scoped /goal command— CRITICAL, blast radius = 140, touching the hooks execution pipeline
The root cause: qwen-code is a CLI + Core + VSCode extension multi-surface project. Functions like loadCliConfig, LoadedSettings.loadSettings, and sendMessageStream are natural convergence points — different contributors touching these hub functions from feature branches inevitably get clustered into one connected component.
Pushing Results to GitHub
CodeGraph doesn’t stop at analysis — it pushes results directly to GitHub via codegraph pr-review label:
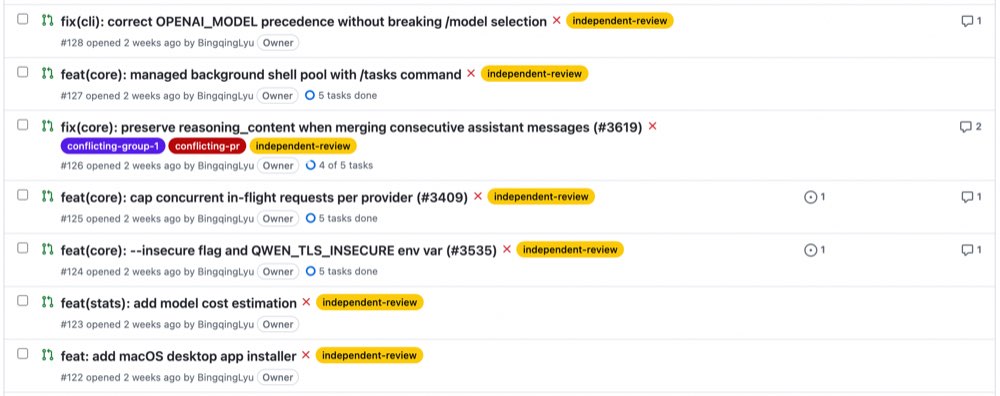
- Labels each PR with its classification (
auto-merge-candidate/independent-review/conflicting-group-N) — visible directly in the PR list. - Posts comments on conflict-group PRs listing specific conflicting PR numbers and shared function names. Contributors see “Your changes potentially conflict with #3455 and #2220 on function
loadCliConfig” without maintainers lifting a finger.
A --dry-run mode lets you preview before execution:
codegraph pr-review label --db .codegraph --dry-run
Why Graph, Not LLM?
The natural question: why not just throw all 146 diffs at an LLM?
The answer is structural. LLMs process text sequentially — each invocation sees one PR’s diff in isolation. To detect that #3982 and #4088 both modify loadCliConfig, you’d need to feed all 146 diffs into a single context (impossible at current context lengths) or build an explicit external index (which is exactly what a graph database is).
CodeGraph flips the model: structural analysis first, LLM second. Risk scoring, conflict detection, and blast radius are pure graph queries — zero tokens. The LLM budget gets saved for the PRs that actually need deep semantic reasoning: “Is this refactor safe? Does this new error handling cover all edge cases?” Graph analysis tells you where to look; the LLM tells you what to think about what you find.
This isn’t a replacement for AI Code Review — it’s the upstream infrastructure that makes AI Code Review tractable at scale.
Takeaways
For maintainers of active projects: If your PR queue regularly exceeds what you can mentally model, graph-based conflict detection gives you the “map of the battlefield” before you start reviewing. The 21% auto-merge identification alone justifies the setup.
For teams using AI Code Review tools: CodeGraph is the pre-filter that tells you which PRs to feed to your LLM reviewer and in what order. Don’t spend tokens on PRs that are safe to merge, and don’t review PRs in isolation when they have hidden dependencies.
For anyone building developer tooling: The pattern of “model code as a graph, query relationships as Cypher” is broadly applicable beyond PR review — dead code detection, impact analysis, architectural enforcement, bug root cause tracing. The CodeGraph skill documentation covers the full capabilities.
Try It on Your Own Repository
# Install
pip install codegraph-ai
# Index your repository
codegraph init --repo . --lang auto --commits 500
# Run PR review
codegraph pr-review prepare --db .codegraph --repo owner/repo
codegraph pr-review label --db .codegraph --repo owner/repo --dry-run
The full analysis toolkit — call graphs, dead code, architectural reports, module coupling, bug root cause tracing — is documented in the CodeGraph skill reference. The underlying graph engine NeuG is open-source and designed for embedding into developer tools.
Links: NeuG · CodeGraph · QwenLM/qwen-code